We’ve heard some people are having a few small issues with getting AWS up and running. I’ve whipped up a quick guide to get you up and running, for FREE, on AWS within a few minutes. Let’s get started.
1.) Sign Up with Amazon AWS
First you need to get signed up on Amazon in order to use their accounts. Head on over to http://aws.amazon.com/ to create an account. Creating an account is 100% free, even though they do ask for your credit card. Click on the ‘Get started for free’ button in the middle of the page. From there you’ll be taken through a quick registration.
2.) Launch Your Instance
There are are tons of different instances you can choose from. For this tutorial we’ll just give you a simple Ubuntu 12 image. Click https://console.aws.amazon.com/ec2/home?region=us-east-1#launchAmi=ami-3bec7952 this will take you to the launch instance screen:
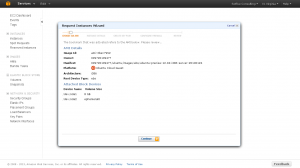
Click on “Continue”. On this screen for now just make sure that the Instance type (top right of screen) is “T1 Micro…”. This is their free tier. You get 720 hours of run time for free on it. The other options on this screen allow you to customize the number of instances and their location, but for now just click “Continue”.
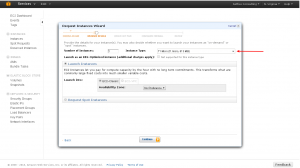 This screen is the advanced options screen where you can select some extra options such as the kernel and monitoring for the instance. The defaults here are fine, so just click “Continue”.
This screen is the advanced options screen where you can select some extra options such as the kernel and monitoring for the instance. The defaults here are fine, so just click “Continue”.
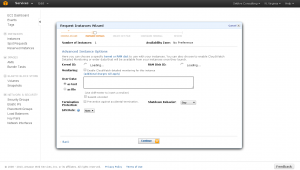 This screen will let you configure the storage for your instance, again the defaults are fine just click “Continue”.
This screen will let you configure the storage for your instance, again the defaults are fine just click “Continue”.
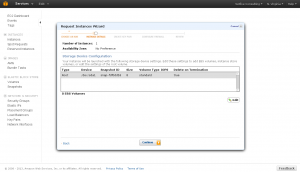 This screen you can put different tags on your instance. If you have a ton of instances it can be helpful to tag them, however as this is your first and only instance, no need to do anything other than click “Continue”.
This screen you can put different tags on your instance. If you have a ton of instances it can be helpful to tag them, however as this is your first and only instance, no need to do anything other than click “Continue”.
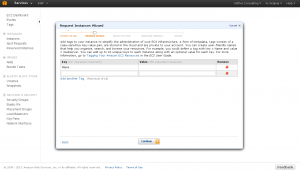
This screen is important. You are going to setup your SSH keys to access the server here. Amazon does not launch the server with passwords, instead is uses https://wiki.archlinux.org/index.php/SSH_KeysSSH Keys. These let you identify with the server without having to specify a password. Read up on them, their really helpful.
You’ll want to click “Create a new Key Pair”. Amazon does not currently let you upload your own public ssh key, you must use one stored on your account.“ Enter whatever name you want for the pair and click “Create & Download your Key Pair”. This will download a file to your computer.
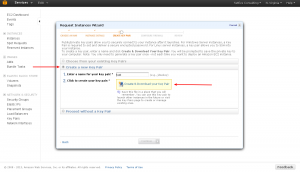
You’ll be automatically advanced to the next screen when is has downloaded. Here you’ll configure which security group you want the server to be in. A security group is pretty much just a set of firewall settings. Use the “default” group. Click “Continue.”
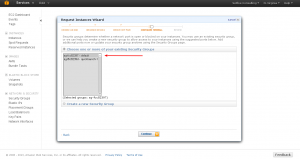
It’ll allow you to review your settings and you can click “Launch”
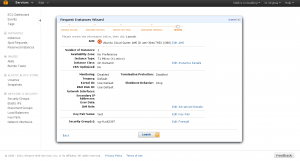
3.) Connecting to your Instance
Your instance is now being launched. You’ll see a “pending” on the screen under state until it is fully up and running.
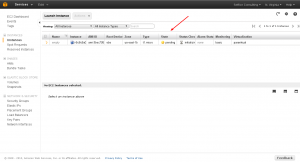
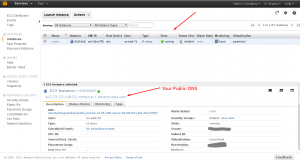
Once it is running the state will change to “running”. Click on the server. At the bottom of the screen you’ll see information about the server. At the top of it under the top line “EC2 Instance ….” there is a URL. This is your servers public DNS record. You’ll use this to connect.
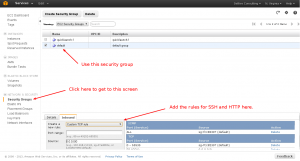
 Before you can connect to your server you need to update your default security group to allow SSH. On the left side of the window click on “Security Groups”. Click default. In the bottom pane click “Inbound”. Select “SSH” in the dropdown for “Create a new rule:”. Click the “Add rule” button. Then do the same but for “HTTP”. At this point click “Apply Rule Changes”. If you do not do this, it will NOT save your updates.
Before you can connect to your server you need to update your default security group to allow SSH. On the left side of the window click on “Security Groups”. Click default. In the bottom pane click “Inbound”. Select “SSH” in the dropdown for “Create a new rule:”. Click the “Add rule” button. Then do the same but for “HTTP”. At this point click “Apply Rule Changes”. If you do not do this, it will NOT save your updates.
 Now open your terminal. Navigate to where you downloaded the file from earlier. Now it is time to SSH into your server. You may encounter a permission error, if you do run the chmod command from the gist below.
Now open your terminal. Navigate to where you downloaded the file from earlier. Now it is time to SSH into your server. You may encounter a permission error, if you do run the chmod command from the gist below.
daum@daum ~ $ ssh ubuntu@ec2-23-22-148-92.compute-1.amazonaws.com -i test.pem
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: UNPROTECTED PRIVATE KEY FILE! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
Permissions 0644 for 'test.pem' are too open.
It is required that your private key files are NOT accessible by others.
This private key will be ignored.
bad permissions: ignore key: test.pem
Permission denied (publickey).
daum@daum ~ $ chmod 0600 test.pem
daum@daum ~ $ ssh ubuntu@ec2-23-22-148-92.compute-1.amazonaws.com -i test.pem
Welcome to Ubuntu 12.04.1 LTS (GNU/Linux 3.2.0-36-virtual i686)
Congratulations, you’re now on your own server!
4.) Installing the Basics
Now that you are on your server you need to install the LAMP stack. The next steps we’ll do is have you become the super user, run apt-get and install the LAMP software. apt-get is a package/software manager.
// Become the super user.
ubuntu@ip-10-202-91-158:~$ sudo -s
// Update apt-get so that it has the most recent information
root@ip-10-202-91-158:~# apt-get update
Ign http://us-east-1.ec2.archive.ubuntu.com precise InRelease
...
// We now tell it to install the lamp server software BE SURE TO INCLUDE THE "^"
root@ip-10-202-91-158:~# apt-get install lamp-server^
...
3 upgraded, 27 newly installed, 0 to remove and 58 not upgraded.
Need to get 43.4 MB of archives.
After this operation, 115 MB of additional disk space will be used.
Do you want to continue [Y/n]? y
// Enter your MySQL password when prompted.
5.) View Your LAMP Server
You’ve now setup MySQL, Apache2, and PHP. You can verify Apache is running by going to your public DNS in your browser. You should see the following screen.
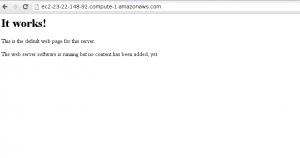
Congratulations!
You now have a fully functional LAMP web server. To modify the files that are being served you’ll need to go to the webroot on the filesystem at “/var/www”.
Don’t forget to turn your instance off, as once your free tier runs out they will charge you. When you turn off your instance you will not be able to recover anything on it, so make sure if you have any files you want to keep you download them first.
Congrats on launching a LAMP server on AWS. Good luck and let us know if we can help you out on AWS or your next project!
Want to learn how to do other things on AWS? Leave us a comment and we’ll do our best to help out!