Symfony2: Outputting form checkboxes in a hierarchy
Recently when I was working on a client project we had a bunch of permissions which had a hierarchy (or tree structure). For example, you needed Permission 1 to have Permission 1a and Permission 1b. In the examples below lets assume $choices is equal to the following:
<?php
$choices = [
'Permission 1' => 'Permission 1',
'Permission 1 Sub-Permissions' => [
'Permission 1a' => '1a',
'Permission 1b' => '1b'
],
'Permission 2' => 'Permission 2',
'Permission 3' => 'Permission 3',
'Permission 3 Sub-Permissions' => [
'Permission 3a' => '3a',
'Permission 3b' => '3b'
]
];At first, I used the built in in optgroups of a the select box to output the form, so it was clear what permissions fell where. My form would look similar to:
<?php
class Form extends AbstractType
{
public function buildForm(FormBuilderInterface $builder, array $options)
{
$builder->add('permissions','choice',['choices' => $choices, 'multiple' => true]);
}
}Multiple select boxes aren’t the easiest to work with as we all know. Also, it isn’t as easy to visually see the difference as the height of the select box could not be long enough to show you what an optgroup’s title is. Instead, I decided to use the checkbox approach. Issue with this, the current Symfony2 form themes don’t output checkboxes in groups or with any visual indication of the hierarchy. I ended up creating my own custom field type so I could customize the way it renders globally via the form themeing. My custom type just always set the choice options to expanded and multiple as true. For the actual rendering, below is what I ended up with.
{% block checkbox_hierarchy_widget %}
<ul class="listless spaced-listless" id="mainList">
{% for choiceOrOptionGroup,children in form.vars.choices %}
{% if children is iterable %}
<ul>
{% for child,choiceView in children %}
<li>
<label class="checkbox">
{{ form_widget(form.offsetGet(child)) }}
{{ form.offsetGet(child).vars.label }}
</label>
</li>
{% endfor %}
</ul>
{% else %}
{# If not first loop, close previous <li> #}
{% if not loop.first %}
</li>
{% endif %}
<li>
<label class="checkbox">
{{ form_widget(form.offsetGet(choiceOrOptionGroup)) }}
{{ form.offsetGet(choiceOrOptionGroup).vars.label }}
</label>
{% endif %}
{# Last of the loop, there will be an open <li>, close it. #}
{% if loop.last %}
</li>
{% endif %}
{% endfor %}
</ul>
<script type="text/javascript">
$("#mainList").children('li').find('input:first').on('change',function(e,isPageLoad){
var children = $(this).parents('li:first').find('ul').find('input');
if($(this).is(':checked'))
{
children.prop('disabled',false);
if(!isPageLoad)
children.prop('checked',true);
}
else
{
children.prop('disabled',true).prop('checked',false);
}
}).trigger('change',[true]);
</script>
{% endblock %}The above is assuming you are using bootstrap to render your forms as it has those classes. My listless class just sets the ul list style to none. The code should be fairly easy to follow, basically it goes through and any sub-array (an optgroup) it will nest in the list from the previous option. This method does assume that you have the ‘parent’ node before the nested array. I also in the bottom have some javascript that basically makes sure that you can’t check off a sub-group if the parent is not checked. When you first check the parent, it selects all the children. For the example I just put the javascript in there, it uses and id attribute, so you can only have one of these per page. If you were using this globally, I’d recommend tagging the UL with a data attribute and moving the javascript into a global JS file.
Since a picture is worth a thousand words, here is an example of what it looks like working:
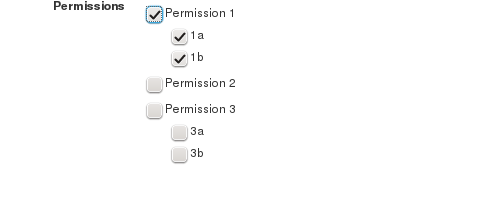
Let me know if you have any questions! Happy Friday.
