One of our new projects here at Setfive is a service that will allow people to create a subscription that will condense AWS product updates into a single email notification with the user’s chosen frequency. An important aspect to a product like this is a captivating sign up — we wanted to include a clean and dynamic sign up section on the website that would help to entice people to sign up and use the product.
This sign up form involves two side by side lists of ‘sources’ you would like updates about (i.e. Amazon EC2, Amazon Lambda, Amazon SNS), a textbox for your email, and a button to submit. The left side Sources are your options, which you can be adjusted via search or selecting different categories. The right side shows your selected sources — clicking a source will select it and move it to the right side, and vice versa to deselect one of your choices:
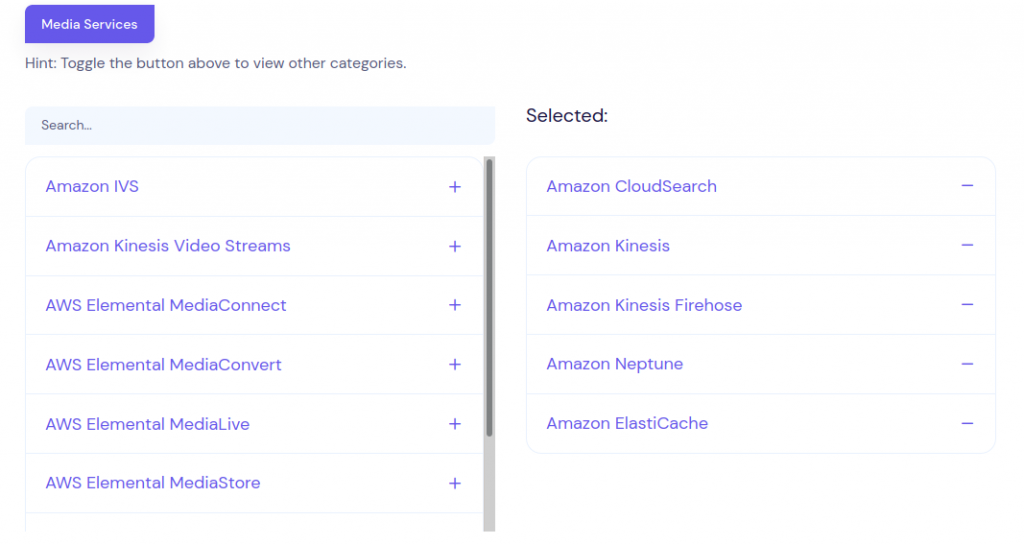
The majority of the project is handled by Symfony — Symfony is perfect for creating rather generic data entry forms made up of different input types such as textboxes, radio buttons, and select boxes. However, we wanted our sign up section to be far more dynamic than what would be easily built through Symfony’s FormBuilder.
Enter Vue.js: a JavaScript framework that can be easily integrated within a traditional web app. If you keep up to date with our Setfive blog posts, you may have seen my last blog about getting started with Vue.js. One of the key benefits of Vue.js is the ability to reuse/combine Vue components with each other and with Symfony’s forms — this allows us to reap the benefits of a dynamic/reactive Vue component as well as the automatic data validation and creation of Symfony.
The Goal:
We at Setfive love Symfony and to stay consistent, we try to use Symfony wherever possible. We wanted to reuse the ‘source select’ portion of the sign up section to allow existing users to edit their subscriptions and create new ones. However, for a registered user the create and edit subscription forms don’t require an email field and we’d instead want to immediately present ‘name’ and ‘frequency’ fields. his being the case, we knew combining our ‘source select’ Vue component with a Symfony form would be our best option — Symfony forms allow for much simpler data validation and can be displayed simply using Twig helpers.
With a combination of Symfony and Vue, we were able to build a dynamic source selecting component with Vue and allow Symfony to validate the selected sources, the name, and the frequency automatically without any extra work.
The Solution:
The first thing we needed to do was split our existing ‘source select’ component up so that the double list selector is independent from the other fields on the sign up form. Fortunately, it is simple to create parent and child Vue components and pass data from child to parent. This is done through Event Emitting: when a source is selected in the child component (source select), that ‘event’ and its data is emitted to the parent component (form composed of source select + email field and submit button).
It is a bit more complicated to synchronize this data with a Symfony form. To solve this problem, a few steps were needed.
First, we had to see what a form would look like if we did this without Vue — in other words, if we created a form and allowed you to use checkboxes to select your sources, what would the HTML elements of the individual sources look like when selected/not selected?
<input type="checkbox" id="subscription_edit_sources_5" name="subscription_edit[sources][]" class="form-check-input" value="5" checked="checked">Our Symfony Form type ended up looking like:
Next, our Subscription form needs to include that form element (sources), but not actually render it on screen. Via Twig:
{% do form.sources.setRendered %}This way, ‘sources’ is a form element whose data will be submitted, but not displayed via Twig.
Finally, we need to handle the logic of sources being selected and deselected. By tracking the ID of each source, we can create hidden HTML elements containing the exact same data that would be present if we were rendering the form entirely with Symfony and Twig.
When a source is selected, our parent component receives that data and we create the corresponding element, without displaying it (class=”d-none”):
$("#subscription-form")
.append($('<input id="source_'+source.id+'" type=text class="d-none"/>')
.attr('name', 'subscription_edit[sources][]')
.val(source.id)
.prop('checked', true));When a source is deselected, we simply delete that element:
$("#source_"+source.id).remove();Once a user hits submit, the form data containing those hidden input elements is compiled and the ‘sources’ form element mentioned above will now contain a list of the source IDs. Behind the scenes, Symfony converts those IDs to their corresponding Source object and Voila! Your subscription now contains the sources you chose!
Have any questions or feedback? Let me know in the comments!


