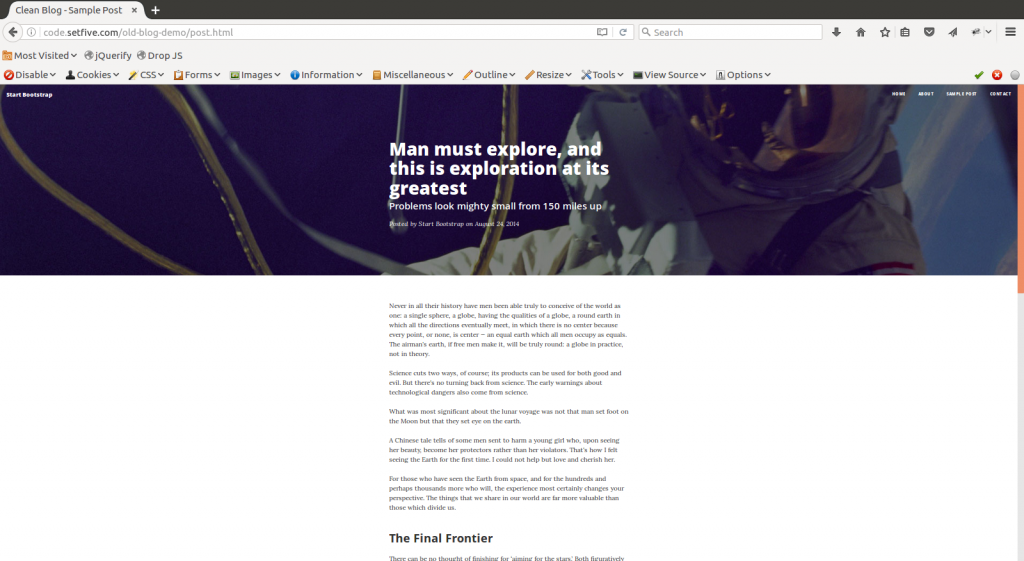
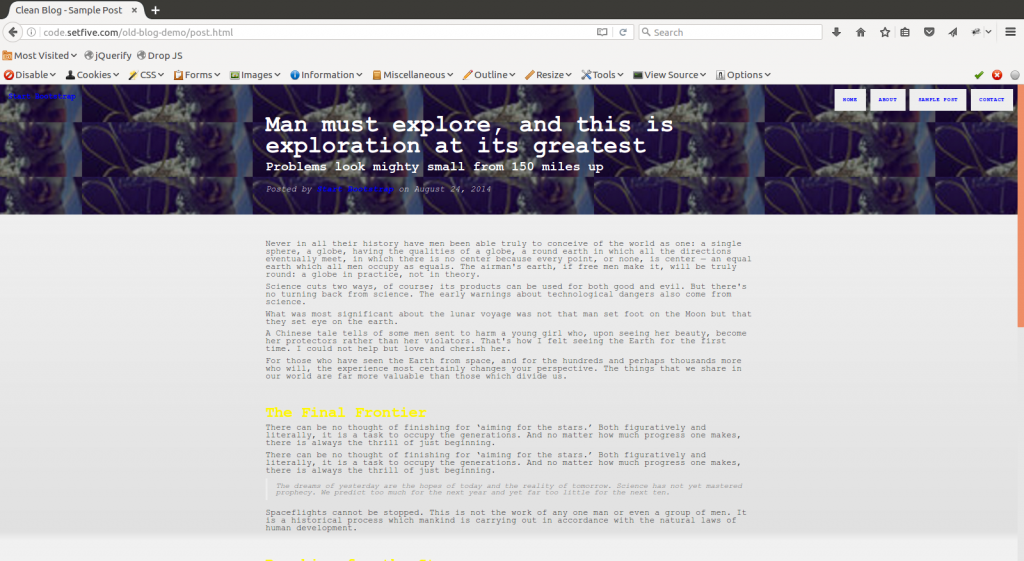
QA: An afternoon with the Rainforest QA test builder
Even in 2019, software testing is still a challenge for a lot of small companies. Testing is usually not prioritized amongst small teams. Small teams frequently lack a dedicated QA resource, this causes writing good tests to be a unique skill in itself. Because of this, teams will end up with maturing software products that have few or no tests. As development continues, the downside is that there is an increased potential for bugs to enter the product. So, how can small teams tackle this challenge? As the software development industry has evolved, the industry has developed a wide array of quality assurance (QA) tools and techniques. Broadly, these tools can be categorized into two buckets - manual (human) testing and automated testing.
Manual / human testing is essentially exactly what it sounds like. A human QA engineer manually executes a list of steps, evaluates the results, and decides if the tested software is passing. Manual testing is relatively easy to start because non-technical resources can develop and execute the tests. However, as the test suite grows, teams run into issues because they’re limited by how many QA resources they have. This leads to teams only running tests before certain deployments, causing them to miss bugs.
In contrast to manual testing, automated testing is typically entirely code based. A QA engineer writes tests in a general purpose programming language. This asserts that the tested software is still working as anticipated. Since the tests are executed by a computer, this approach does not suffer from the limitation highlighted above. The trade off is that, because the tests are written in a programming language, technical resources are required to develop the tests.
So, what if there was a hybrid approach that combined some aspects of each approach? Well, that’s why you’re here! Say hello to RainforestQA.
What is RainforestQA?
RainforestQA is a SaaS product that incorporates manual and automated software testing approaches. RainforestQA offers a free trial, followed by a pay-as-you-go billing model, where you only pay for the resources being used. RainforestQA tests are executed by an automated system, or human testers, depending on how the test is constructed.
What does an automated RainforestQA test look like?
The tests are composed of a series of steps, which describe actions or assertions, that the automated system must take. The steps can include, “load this page” or “scroll the page down,” while the assertions are things like, “see a button” or “confirm text on the page.” When any one of these steps / assertions fail, the entire test fails, which indicates that something is broken in the software being tested.
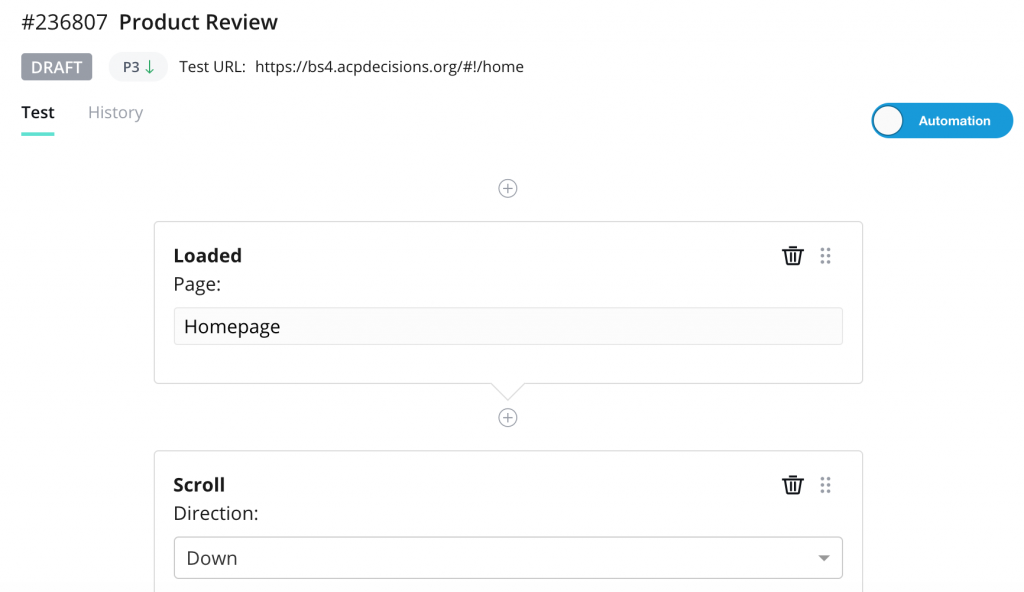
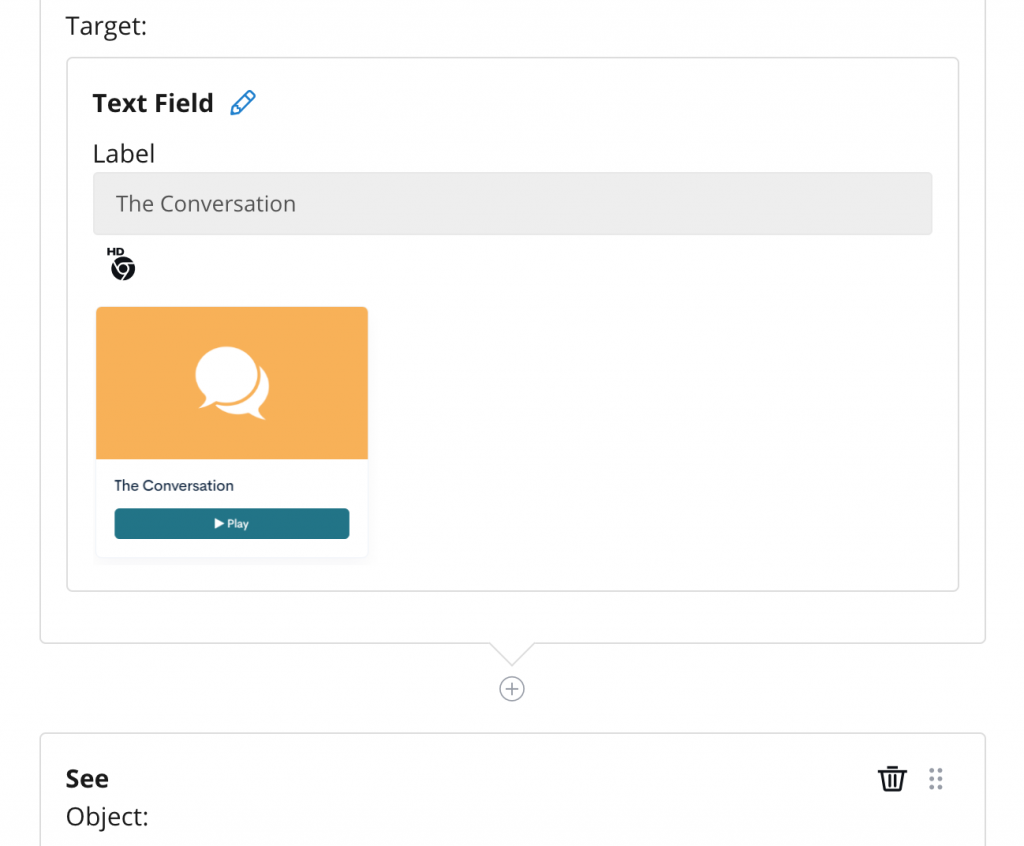
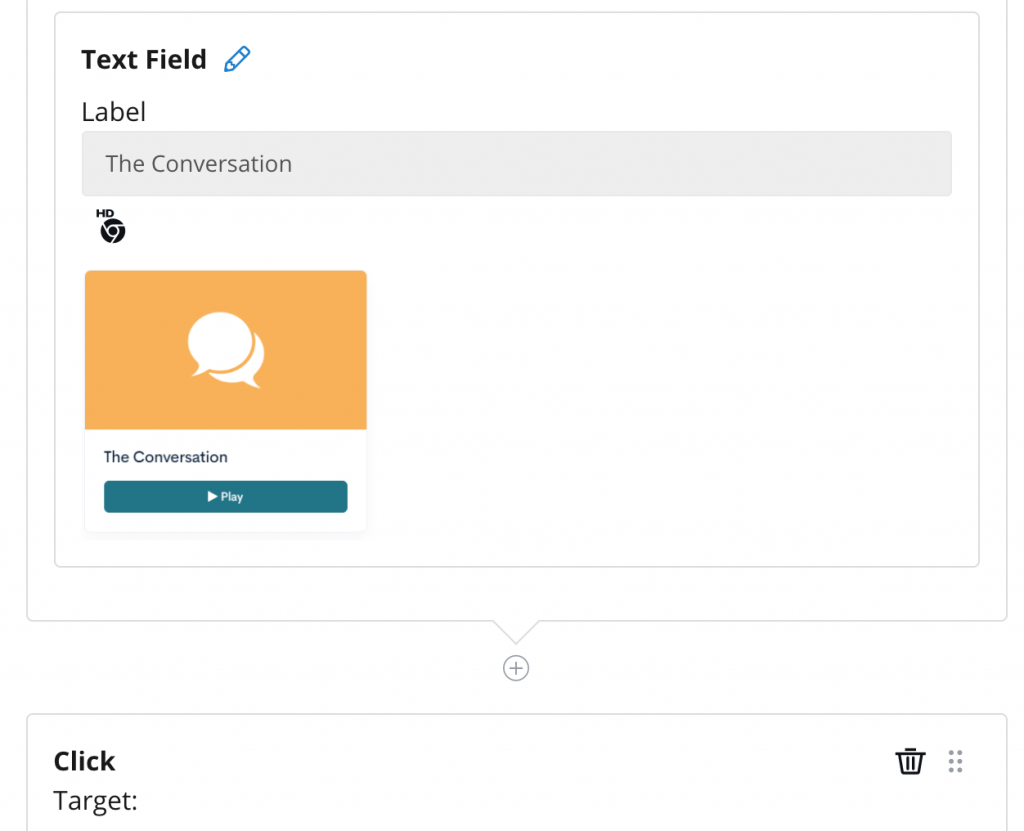
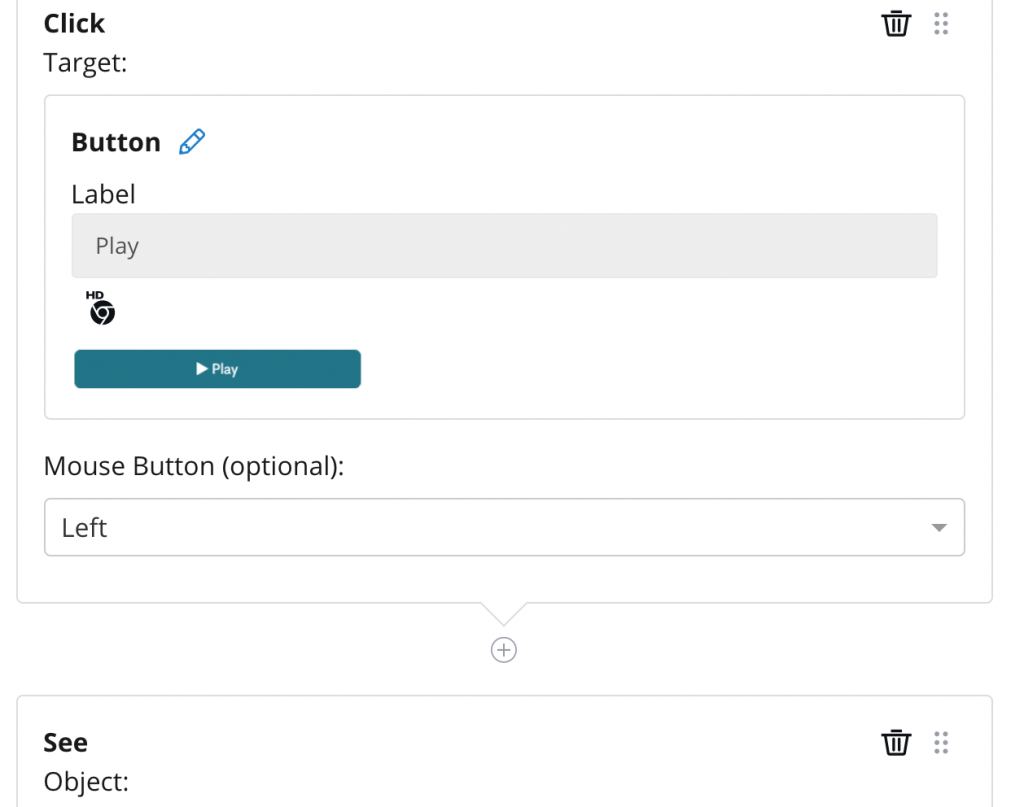
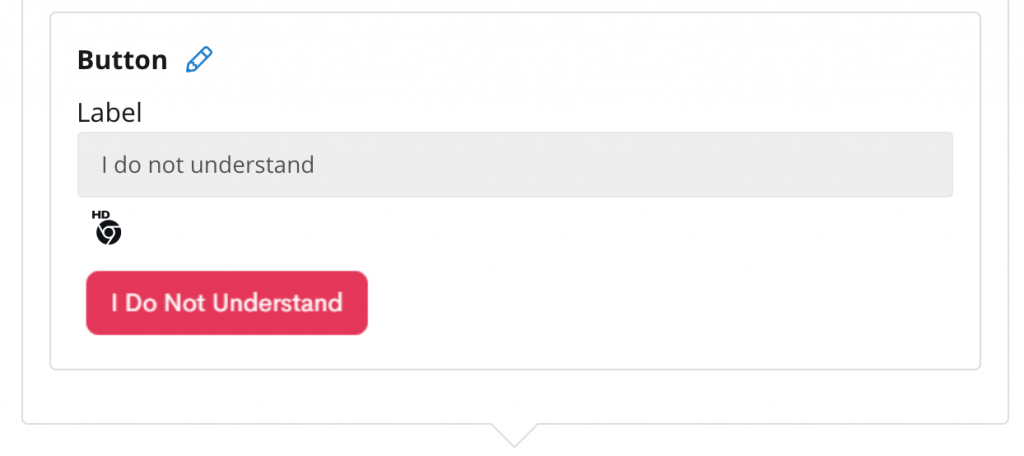
What’s the process of building these automated tests?
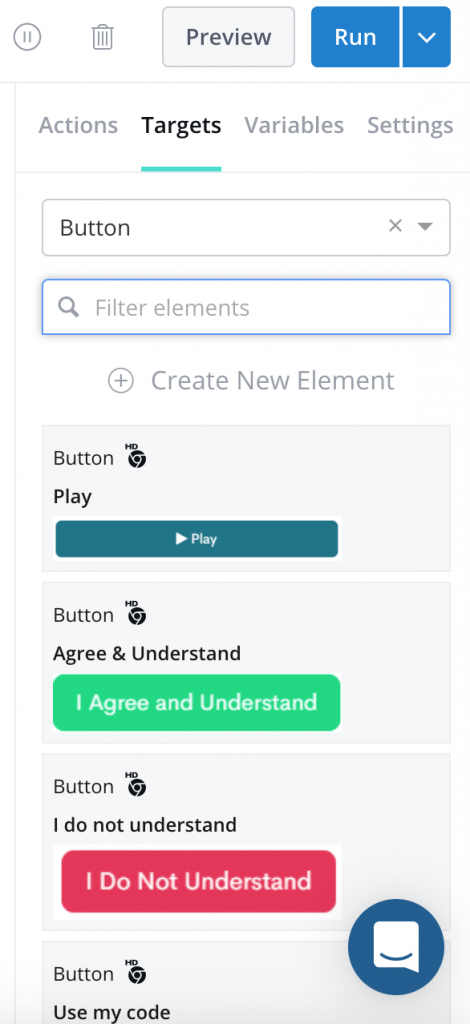
Building automated tests on the Rainforest QA differs depending whether it is written in Plain English or Beta Language. When constructed in English, the user is constructed to write their own question and answer for each step. If the test is written in Beta Language, an action can be selected from the sidebar on the right, followed by a target, which is also listed on the same sidebar. The types of actions and targets can be adjusted depending on the test and what is being assessed.
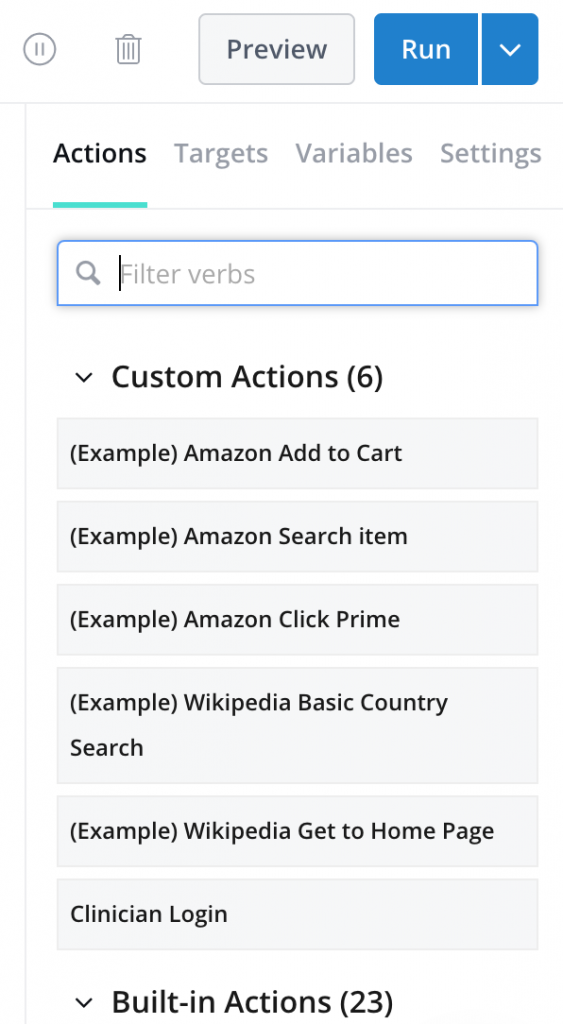
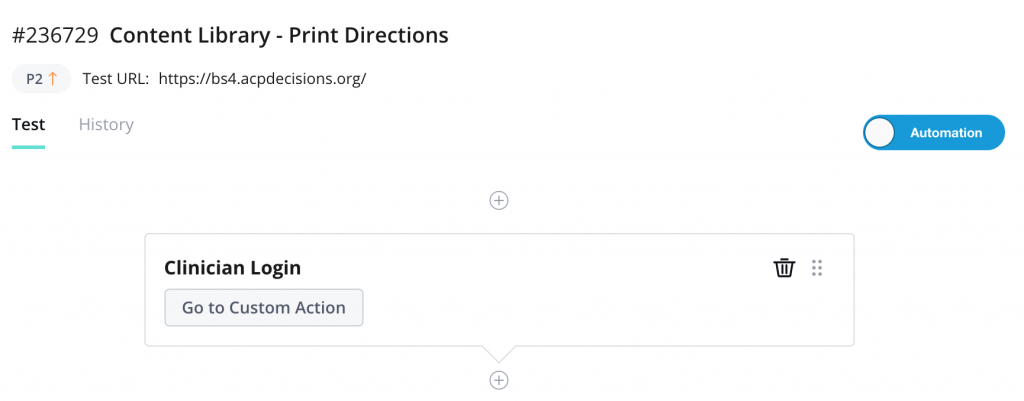
When composing certain tests in Beta, you will find that the same sequence of steps are needed. Instead of writing out every individual step, over and over, the “custom actions” feature can be used. This feature enables a series of steps to be grouped together, which saves a lot of time and energy. I found the custom actions feature exceptionally useful when a login was required at the beginning of the test. However, a flaw in this feature can appear if the actual custom actions, itself, is being tested. The test results for a custom action will not appear unless the results page is reloaded. While this is a very small detail, it was a fairly substantial inconvenience for me. The rest results appeared as though the custom action test was in progress for over an hour, when in actuality, the test results were returned within a few minutes, they just did not appear until the page was refreshed.
How does the back-and-forth work between users and Rainforest QA engineers?
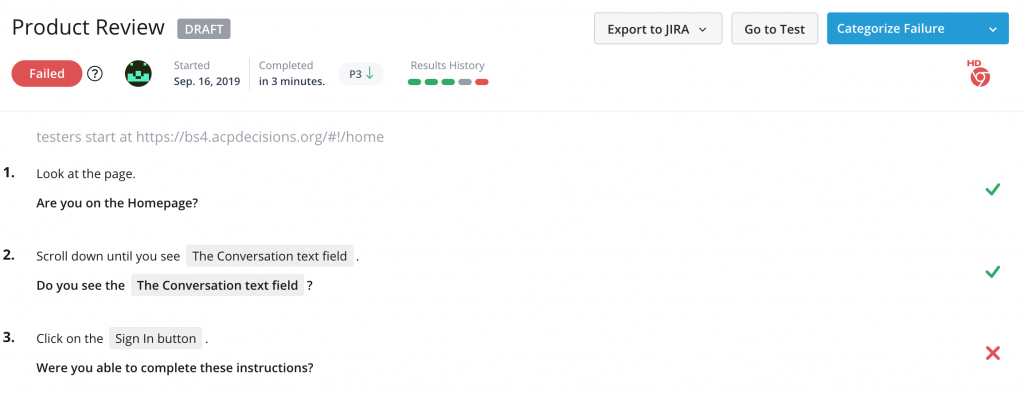
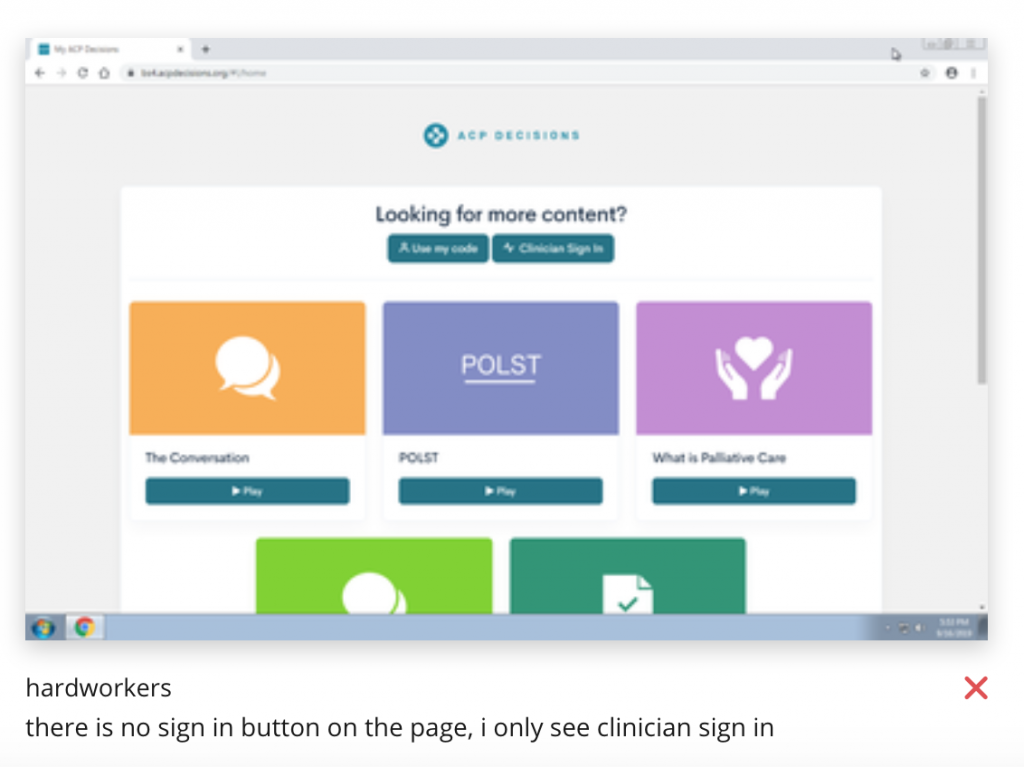
When running a test, everything is sent through a real and active test team of almost 60,000 testers. The test team provides clear feedback in a timely manner. If the test is passed, it will appear in green (as pictured above.) If the test is failed, it will come back in red. If the “Go To Test” button is selected, the test feedback can be viewed. Specific comments and critique are given on the particular step that caused the test to fail. Additionally, all of the tests and results are automatically recorded and stored in a neat and orderly fashion.
What is the Difference Between Testing Languages?
As discussed, on the Rainforest QA, tests can be written in “Plain English” or “Beta Language.” Writing tests in plain english is faster and easier, but also much more expensive. For a test to be passed in “Plain English,” the tests have to be written and constructed in a very specific way. For example, if you wanted to test the login page while leaving the username or password blank, you cannot use the “type” action to exemplify that you are leaving it empty. With the Beta Language tests, you have to select a specific action from the bar on the right, followed by a target. The only choices are what is already listed. In Beta, you have the option to use custom actions, you can also make new targets, but only by labeling a pre-existing type of target. When conducting a test in beta language, screenshots are used to identify what should be seen/clicked on each page. The downside being, if there are three of the same buttons on one page, you cannot type in directions, nor can you describe which of the three identical buttons needs to be selected.


Conclusion
I haven’t plugged Rainforest into our development workflow, so I cannot speak on the integrations or reporting. However, I would recommend the Rainforest QA to anyone- regardless of their technical ability- that wants to run automated tests on a timely and inexpensive budget. Building tests on this QA very quick and straightforward. While you may find a few complications and specificities on each language, it typically would not take more than one revision to fix the issue.
TL ; DR
Likes:
- Interface is easy to use
- Variety of features available to test
- Access to a test team that provides feedback quickly
- Non-technical users can build tests and test the UI without writing code
- Free trial and then pay as you go pricing
- Custom actions
Dislikes:
- Tests written in Plain English language ask for specific answers on tests which allows a huge margin for error including spelling, spacing, and plurals
- Have to be written and constructed in a very specific way to be passed and you can’t use any screenshots to clarify directions
- Screenshot feature for capturing targets do not always capture / appear
- Cannot specify instructions on Beta language