A couple of months ago I decided to use Scala with the Play Framework for a Bitcoin related project. The decision to use Play was motivated primarily by the goal of implementing a “pure” Bitcoin application, leveraging bitcoinj to interact with the Bitcoin network as opposed to a third party service. Overall, everything was pretty straightforward but one thing that stuck out was how the Play framework handles parsing JSON.
Coming from loosely typed PHP I knew that handling serializing and unserializing of JSON data was going to be different but Play’s approach is a completely new paradigm. If you use Play with Scala, you can handle parsing JSON input back into objects using Scala’s Parser Combinators syntax. I’m going to butcher this description so check the wikipedia entry but the idea is that parser combinators let you “build up” increasingly complex parsers by combining functions that recognize smaller inputs. If you’ve taken a compilers or programming language class, Scala’s parser combinators end up looking a lot like Backus–Naur Form for the input you want to recognize.
Anyway in an effort to learn Scala a bit better and take Parser Combinators for a spin I decided to build out a small project. What I ended up building is a really simple implementation of a Turtle Graphics system. You basically feed it a series of “turtle” commands and it’ll move the “turtle” around on a Swing window drawing some graphics.
Here’s an examples of the input and output:
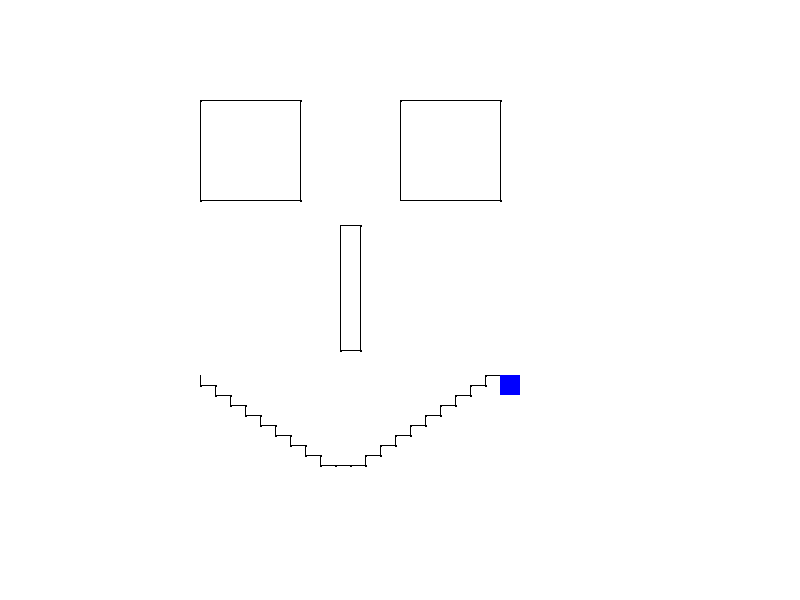
Which was generated by:
Overall, parser combinators seem to be a really powerful Scala feature that would make developing domain specific languages relatively straightforward. Compared to messing around with a parser generator, using parser combinators seems to more closely mirror what the formal grammar of a language would be.
The entire project is available on GitHub. If you clone that project, there’s a runnable JAR which you can run with:
java -jar logoparser.jar /home/ashish/workspace_java/logo-parser/samples/face.txt
You’ll need to provide an absolute path for the “filewatcher” to work. Once the app starts, if you modify the file you specify it’ll repaint the canvas with your updates. Note: I’m not sure why but certain text editors don’t seem to register in the Java “filewatcher” interface so if your updates aren’t showing up try using a different editor.
Anyway, as always I’d love any feedback!


















